1:1 with Dr. Aleena Baby
The Portfolio Project That Gets You Hired
Build a deployed, containerised, interview-ready ML system, guided 1:1 by a Machine Learning Engineer who made the same transition.
1:1 with Dr. Aleena Baby
Build a deployed, containerised, interview-ready ML system, guided 1:1 by a Machine Learning Engineer who made the same transition.
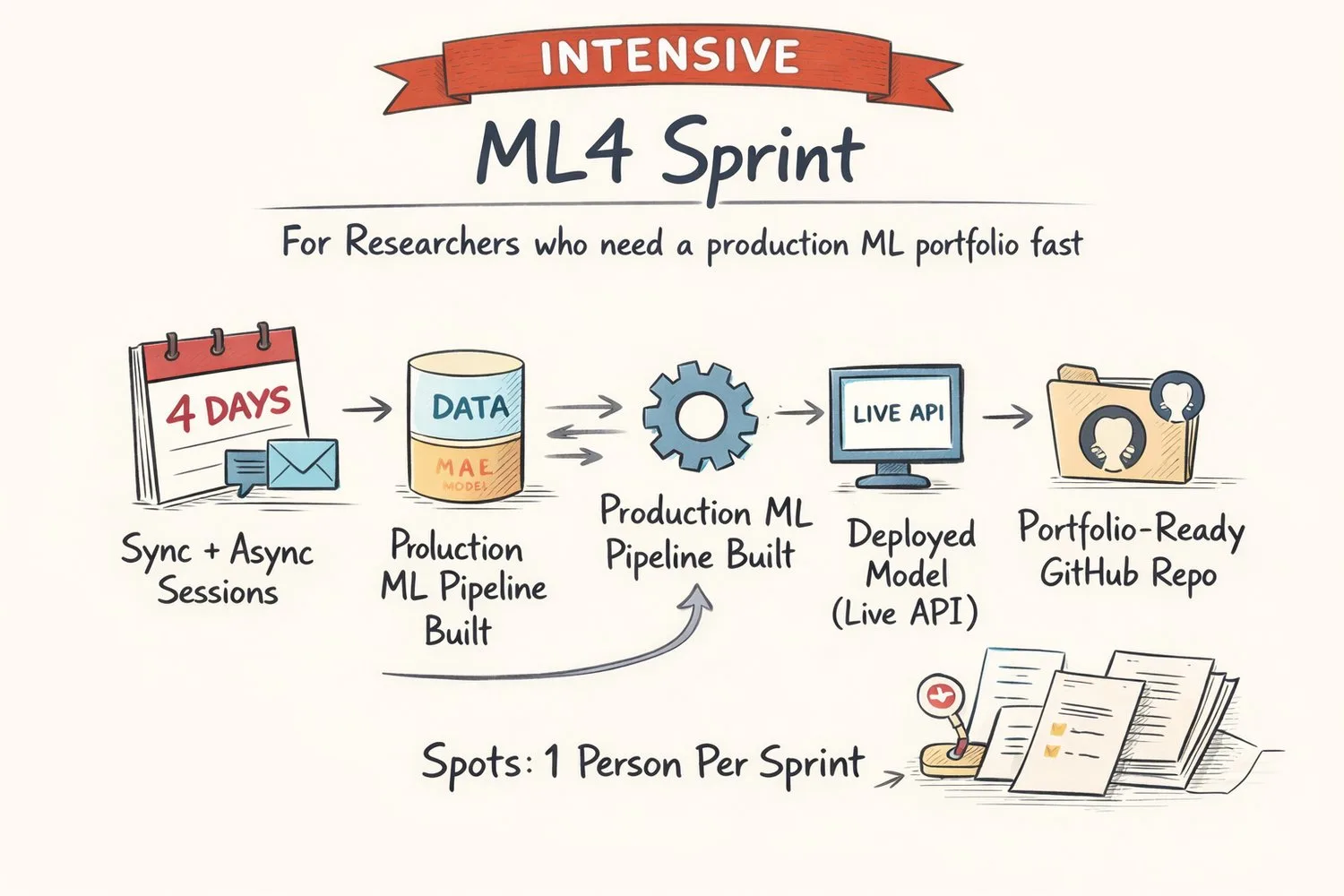
Conflicting opinions, endless tutorials, a hundred must-dos. We cut through the noise and give you clarity: one real project that shows you can track, containerise, and deploy, the proof that opens interviews.
Define the ML problem, load your industrial dataset, analyse it with purpose, and produce a clean EDA notebook with documented decisions. No guessing. Every choice is justified.
Baseline first, always. Then a full sklearn Pipeline with preprocessing, model selection, and every experiment logged in MLflow. Reproducible, explainable, production-ready.
Your model becomes an API. You write the FastAPI endpoint, containerise it with Docker, and deploy it to a live public URL on Streamlit. Anyone can call your model from anywhere.
Structure your GitHub repo like a professional. Write the README that recruiters actually read. Draft your LinkedIn post. Rehearse your 3-minute project pitch for interviews.
Same pipeline. Same deliverables. Same direct access to Dr. Aleena. Different pace based on where you are.
For experienced practitioners who have built ML models before and want to level up to production standards fast.
For researchers who know Python but have never built an end-to-end ML project in production. More time to absorb, practice, and build confidence.
Not sure which track fits? Describe your background in the application. Dr. Aleena will recommend the right one after reviewing your profile.
Everything you’ll use is what actual ML engineering teams use in production. No toy frameworks. All tools are free or have generous free tiers. You will not spend a single euro on infrastructure during this sprint.
This is a 1:1 engagement, not a mass course. We need to see that you have the foundation to get real value from the sprint. Here is what we look for.
The technical bar (Python, pandas, scikit-learn) is covered by your track above. This is about fit.
Not ready yet? Build the foundation first:
Each phase is a focused session with Dr. Aleena. Not a lecture. You build, she guides. Real-time feedback, real problems, real code.
Sent before your sprint starts. Environment setup, prep videos, fundamentals refresher, and a checklist so Phase 1 isn’t wasted on basics.
FastAPI serving template, MLflow tracking boilerplate, EDA checklist, Dockerfile, GitHub repo structure. Yours to keep and reuse.
Every session is recorded. Rewatch any part, revisit the deployment steps, or catch anything you missed in the flow of building.
If anything feels shaky (Python, pandas, sklearn, Git), a reference repo covers the foundations you need before and during the sprint.
Questions after the sprint? Reach out via email or LinkedIn for 30 days. Getting the job matters as much as building the project.
24 chapters. 175+ pages. 100+ code examples. Covering everything from data versioning and experiment tracking to CI/CD pipelines and LLMOps. Yours to keep as a permanent reference long after the sprint ends.
This guide is sold separately. Sprint participants receive it at no additional cost.
Get the Guide
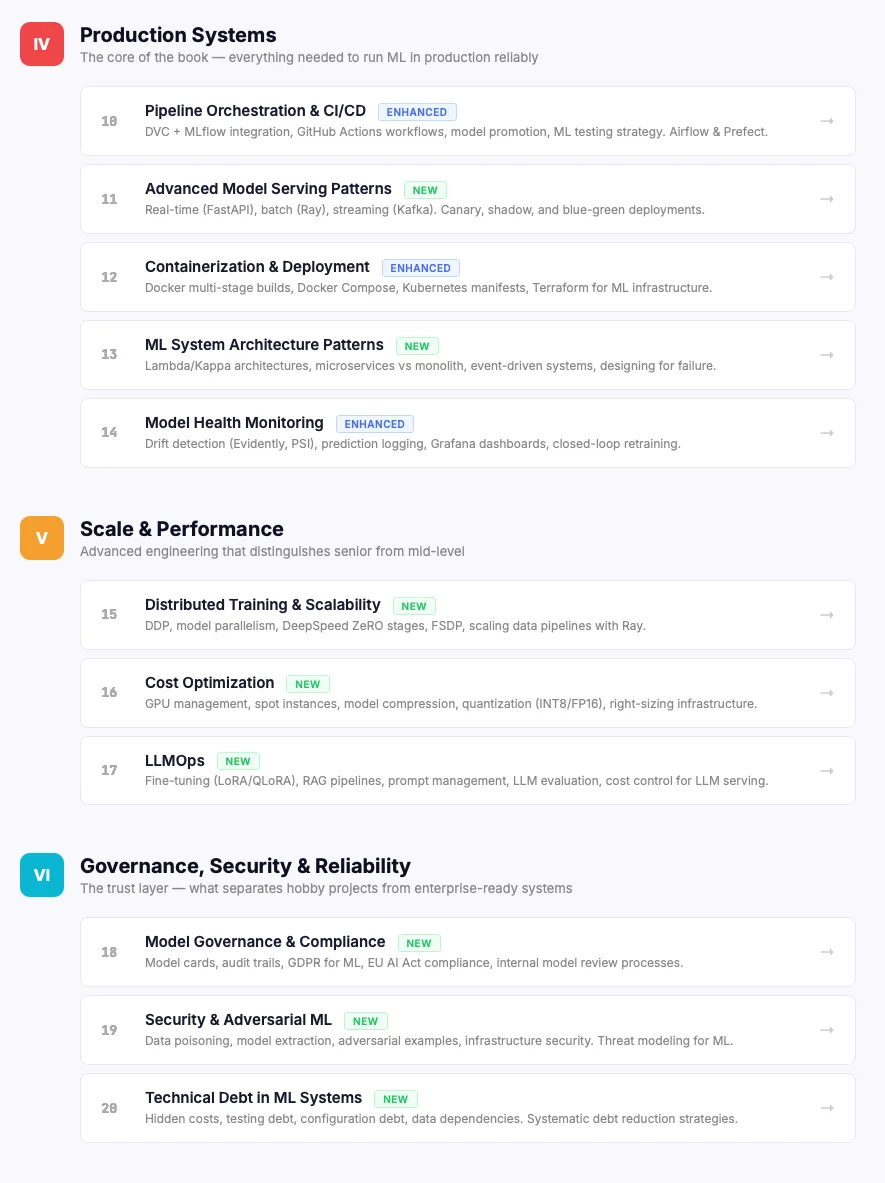
Tap either page to view the full table of contents.
Real domains, real outcomes. Every sprint participant to date has used their project to land industry conversations.
CNC machine sensor data from Bosch
4 interviews and 2 job offers
Probabilistic 24-hour energy demand forecasting for the German grid
5 interviews and 1 job offer
Confidence-scored cell population pipeline with DVC versioning and MLflow tracking
3 interviews landed with this project
Live From the Interview Cycle
Raw updates from inside real interview rounds, not polished testimonials, the actual texts.
Hey, both interviews went well 🙏 beON had quite a lot of questions on ML system design so I answered them using my project structure. The team lead also said he had a look at my project earlier! Enercity: showed my deployed product and since the team was working on grid use cases, they had quite a lot of questions. Next week I’ll hear from both of them. I’ll keep you posted :)14:32 ✓✓
Energy Systems · Hired
Aleenaaa just got the second offer 🥳 The hiring manager pulled up their pipeline diagram and asked how I’d integrate the Bosch CNC project into their setup. I literally walked him through the README from Day 3. He said “this is exactly what we’re trying to build internally.” Negotiating between both this week. Will share the salary stuff once one is signed 🤝11:08 ✓✓
Manufacturing · Hired
First time someone said “show me a project you’re proud of” and I didn’t freeze 🥹 Pulled up the live demo, walked the interviewer through it, ran an actual prediction. He leaned in. Used to be I’d mumble something about “notebooks somewhere” and watch the energy leave the room. Now I’m demoing a live system. Completely different conversation. Got the offer two days later.21:08 ✓✓
Manufacturing · Hired
Everything you wanted to know about the sprint, from prerequisites to outcomes.
You won’t be stuck alone. Every session is live with Dr. Aleena. She guides you through blockers in real time. Between sessions (especially on the 4-week track), you have async support via email.
The sprint is designed so you finish, whether that’s 4 days or 4 weeks. Each phase builds on the last with clear milestones. If something runs over, you have 30-day follow-up access to get it across the line.
No. The expert track is 4 consecutive days. The intermediate track is 4 consecutive weeks with one session per week. Both have a fixed schedule. That structure is what makes it work.
Yes, with one honest caveat. The sprint gives you a deployed model, a professional GitHub repo, resume bullet points, and a rehearsed pitch. Those showcase your expertise during interviews and on your applications. But the project alone is not a job-offer machine. You still need to update your CV, rebuild your LinkedIn, and run a focused application strategy. That’s what gets you in the door. The project is what closes the room once you’re in it.
The sprint covers tabular and industrial data, not yet text data. But the skills (pipelines, deployment, MLOps, portfolio structure) transfer to any ML domain. Previous projects have spanned biomedical, business analytics, and sensor data.
On your own, you’d spend weeks guessing at best practices. Here, you get direct feedback from someone who builds production ML systems and reviews code professionally. Every decision is guided, every shortcut is intentional.
Sessions are scheduled in CET (Central European Time). We accommodate other timezones on a case-by-case basis. Mention your timezone when you apply.
No. Everything runs on free tools: Python, Docker Desktop, VS Code, and free-tier cloud services. The pre-sprint prep portal walks you through setup before your first session.
You should be comfortable writing Python functions, using pandas for data manipulation, and have used scikit-learn at least once. If you’ve completed a data science course or used Python in your research, you’re ready.
If your profile isn’t a fit for the sprint yet, you’ll receive honest feedback on what to work on first. Many applicants start with the self-paced ML Pipeline Guide and reapply when they’re ready.
The sprint is a complete package, not just the live sessions:
The ML4 Sprint is for building something new, not reviewing a project you already have. If you want feedback on an existing portfolio, that is a separate 1:1 session. Book a portfolio review here.
A private engagement built around one participant at a time, not a group course. You leave with a deployed, interview-ready ML system. €499, one-time. Seats open one at a time, so join the waitlist and I’ll reach out the moment the next one is free.
Questions first? Get in touch.
No spam, no weekly emails. I’ll only write when a seat opens. Browse past newsletters on Substack →